AI 常见问题
本文档整理了 PIG AI 平台使用过程中的常见问题和解决方案。
配置类问题
Ollama 配置常见问题
如何在 Mac 上设置环境变量?
如果 Ollama 作为 macOS 应用程序运行,应使用 launchctl 设置环境变量:
- 对于每个环境变量,调用
launchctl setenv:
- 重启 Ollama 应用程序。
如何在 Linux 上设置环境变量?
如果 Ollama 作为 systemd 服务运行,应使用 systemctl 设置环境变量:
- 通过调用
systemctl edit ollama.service编辑 systemd 服务。这将打开一个编辑器。 - 对于每个环境变量,在
[Service]部分下添加一行Environment:
- 保存并退出。
- 重新加载
systemd并重启 Ollama:
如何在 Windows 上设置环境变量?
在 Windows 上,Ollama 会继承你的用户和系统环境变量。
- 首先,通过点击任务栏中的 Ollama 图标来退出 Ollama。
- 启动设置(Windows 11)或控制面板(Windows 10)应用程序,并搜索 环境变量。
- 点击 编辑账户的环境变量。
- 编辑或为你的用户账户创建新的变量,例如
OLLAMA_HOST、OLLAMA_MODELS等。 - 点击确定/应用以保存。
- 从 Windows 开始菜单启动 Ollama 应用程序。
如何在代理后面使用 Ollama?
Ollama 从互联网拉取模型,可能需要通过代理服务器来访问这些模型。使用 HTTPS_PROXY 将出站请求重定向到代理。确保代理证书已安装为系统证书。
避免设置 HTTP_PROXY。Ollama 不使用 HTTP 拉取模型,只使用 HTTPS。设置 HTTP_PROXY 可能会中断客户端与服务器的连接。
在 Docker 中使用代理
可以通过在启动容器时传递 -e HTTPS_PROXY=https://proxy.example.com 来配置 Ollama Docker 镜像使用代理。
或者,可以配置 Docker 守护程序使用代理。使用 HTTPS 时,确保证书已安装为系统证书。如果使用自签名证书,可能需要创建新的 Docker 镜像:
构建并运行此镜像:
Ollama 是否会将我的提示和回答发送回 ollama.com?
不会。Ollama 在本地运行,对话数据不会离开你的机器。
如何在我的网络上暴露 Ollama?
Ollama 默认绑定 127.0.0.1 端口 11434。你可以通过设置 OLLAMA_HOST 环境变量来更改绑定地址。
模型存储在哪里以及如何更改位置?
默认模型存储位置:
| 操作系统 | 存储路径 |
|---|---|
| macOS | ~/.ollama/models |
| Linux | /usr/share/ollama/.ollama/models |
| Windows | C:\\Users\\%username%\\.ollama\\models |
更改位置:
如果需要使用不同的目录,可以将环境变量 OLLAMA_MODELS 设置为你选择的目录。
在 Linux 上使用标准安装程序时,ollama 用户需要对指定目录有读写权限。要将目录分配给 ollama 用户,请运行 sudo chown -R ollama:ollama <directory>。
如何指定上下文窗口大小?
默认情况下,Ollama 使用 2048 个 token 的上下文窗口大小。
使用 ollama run 时:
可以通过 /set parameter 来更改此设置:
使用 API 时:
指定 num_ctx 参数:
如何保持模型在内存中加载或立即卸载?
默认情况下,模型会在内存中保留 5 分钟后才被卸载。
立即卸载:
使用 ollama stop 命令:
通过 API 控制:
使用 keep_alive 参数与 /api/generate 和 /api/chat 端点来设置模型在内存中保持的时间。keep_alive 参数可以设置为:
- 一个持续时间字符串 (例如 "10m", "24h")
- 以秒为单位的数字 (例如 3600)
- 任何负数,这将使模型保持在内存中 (例如 -1, "-1m")
- '0',这将在生成响应后立即卸载模型
示例 (保持加载):
示例 (立即卸载):
通过环境变量控制:
你可以在启动 Ollama 服务器时通过设置 OLLAMA_KEEP_ALIVE 环境变量来更改所有模型加载到内存中的时间。
keep_alive API 参数将覆盖 OLLAMA_KEEP_ALIVE 设置。
如何管理 Ollama 服务器可以排队的最大请求数?
如果发送到服务器的请求数过多,服务器将返回 503 错误,表示服务器过载。你可以通过设置 OLLAMA_MAX_QUEUE 来调整可以排队的请求数。默认值为 512。
Ollama 如何处理并发请求?
Ollama 支持两个级别的并发处理:
- 多模型并发:如果系统有足够的内存(系统内存用于 CPU,VRAM 用于 GPU),可以同时加载多个模型。
- 单模型并行:对于给定的模型,如果在加载时有足够的可用内存,它将被配置为允许并行请求处理。
内存不足时的处理:
如果在加载新模型时内存不足,新请求将被排队,直到有足够空间。先前的空闲模型将被卸载以腾出空间。
服务器设置参数:
| 参数 | 描述 | 默认值 |
|---|---|---|
OLLAMA_MAX_LOADED_MODELS | 可以同时加载的最大模型数量 | GPU 数量的 3 倍 (GPU) 或 3 (CPU) |
OLLAMA_NUM_PARALLEL | 每个模型同时处理的最大并行请求数 | 根据可用内存自动选择 4 或 1 |
OLLAMA_MAX_QUEUE | 在拒绝额外请求之前可以排队的最大请求数 | 512 |
Windows 上使用 Radeon GPU 当前默认为最大 1 个模型,由于 ROCm v5.7 的限制。可以在 Windows 上启用 Radeon 的并发模型加载,但需确保加载的模型数量不超过 GPU 的 VRAM 容量。
Ollama 如何在多个 GPU 上加载模型?
当加载新模型时,Ollama 会评估所需 VRAM:
- 单 GPU 足够: 如果模型可以完全适应任何一个 GPU,Ollama 将在该 GPU 上加载模型以获得最佳性能。
- 单 GPU 不足: 如果模型不能完全适应一个 GPU,它将分布在所有可用的 GPU 上。
更多详细信息请参考:Ollama 官方文档
错误类问题
知识库向量链接错误
问题描述:
当您在 AI 知识库模块进行提问时,如果看到向量错误提示,表明存在向量链接问题。

解决方案:
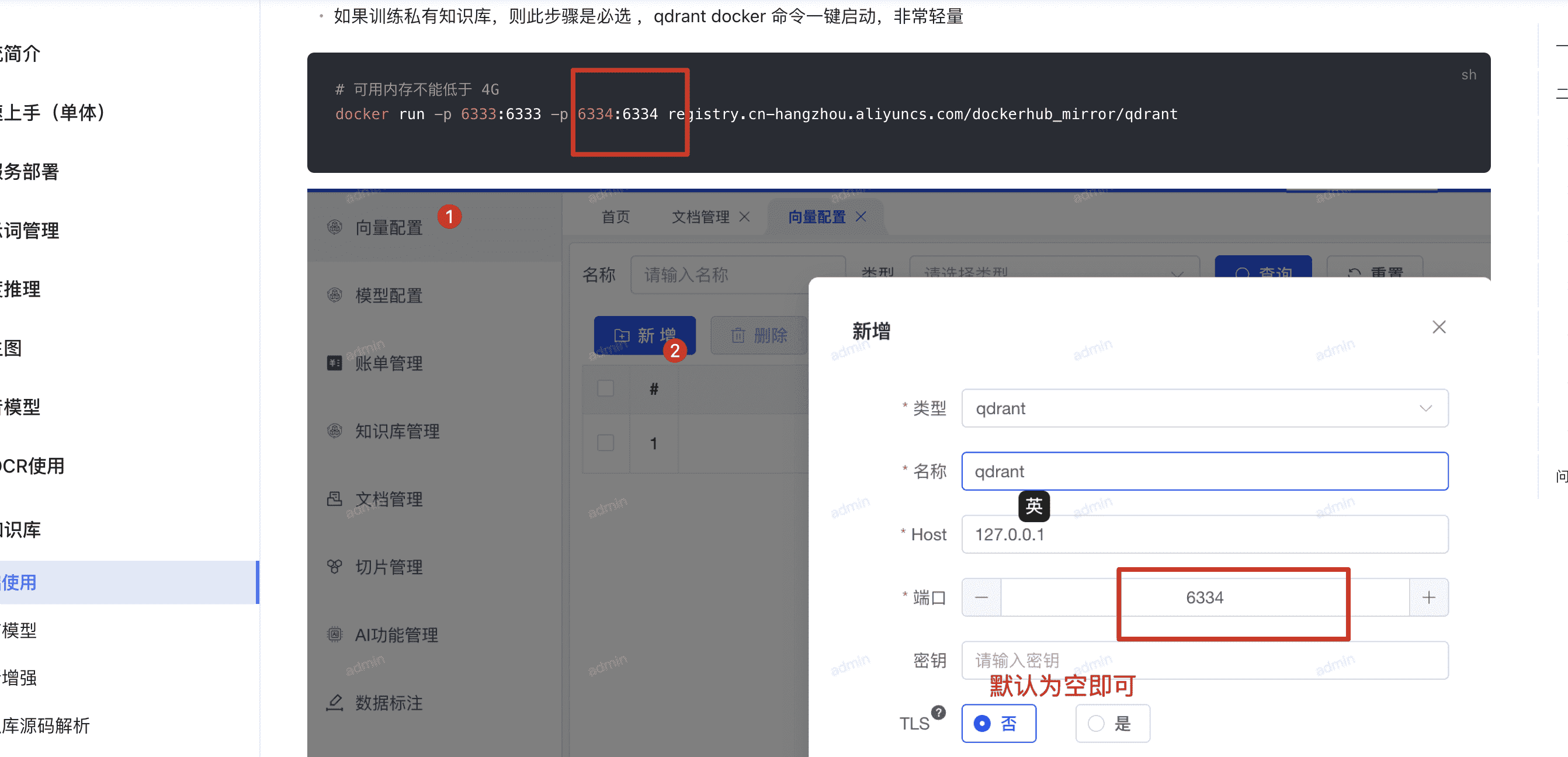
此错误是因为应用没有正确链接到 Milvus 向量库。解决方法:
- 检查向量库配置参数是否正确
- 参考知识库部署文档正确部署 Milvus
- 确保连接参数与下图类似配置:

后台切片训练错误
问题描述:
解决方案:
报错如上,请注意按文档部署 milvus,要求版本 2.5+
请求知识库报错 HTTP2 异常
问题描述:
知识库对话报错:dev.ai4j.openai4j.OpenAiHttpException: 404 page not found
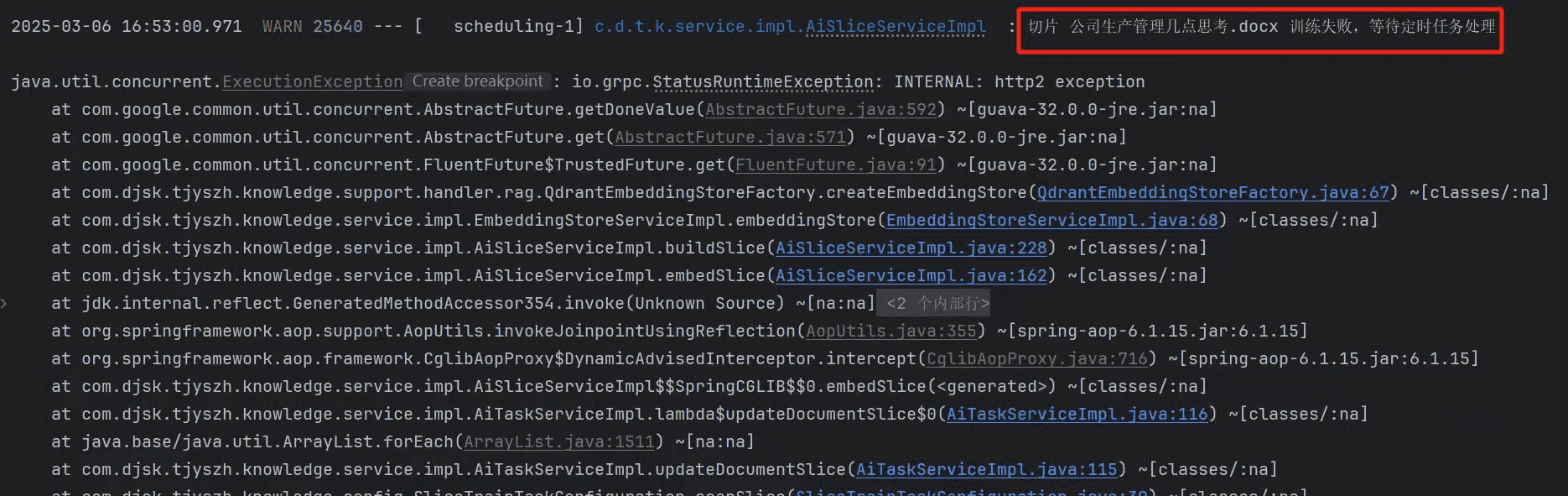
解决方案:
请注意 qdrant 的访问端口是 6334 而不是 6333;这个异常说明是请求错误
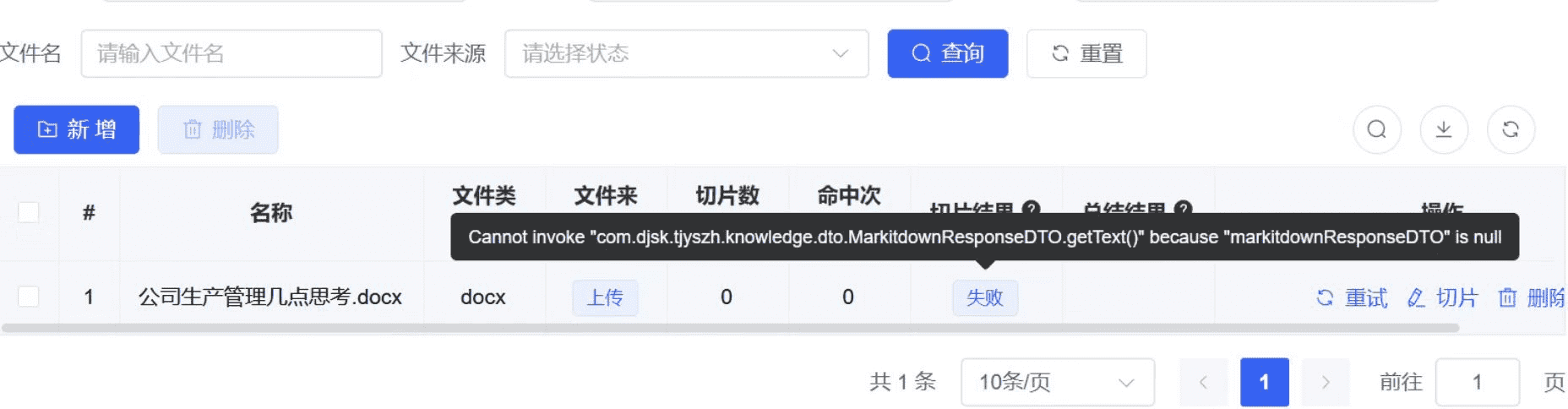
配置 MarkItDown 切片失败
问题描述:
按文档配置解析增强以后,MarkItDown 文档页面 提示切片失败
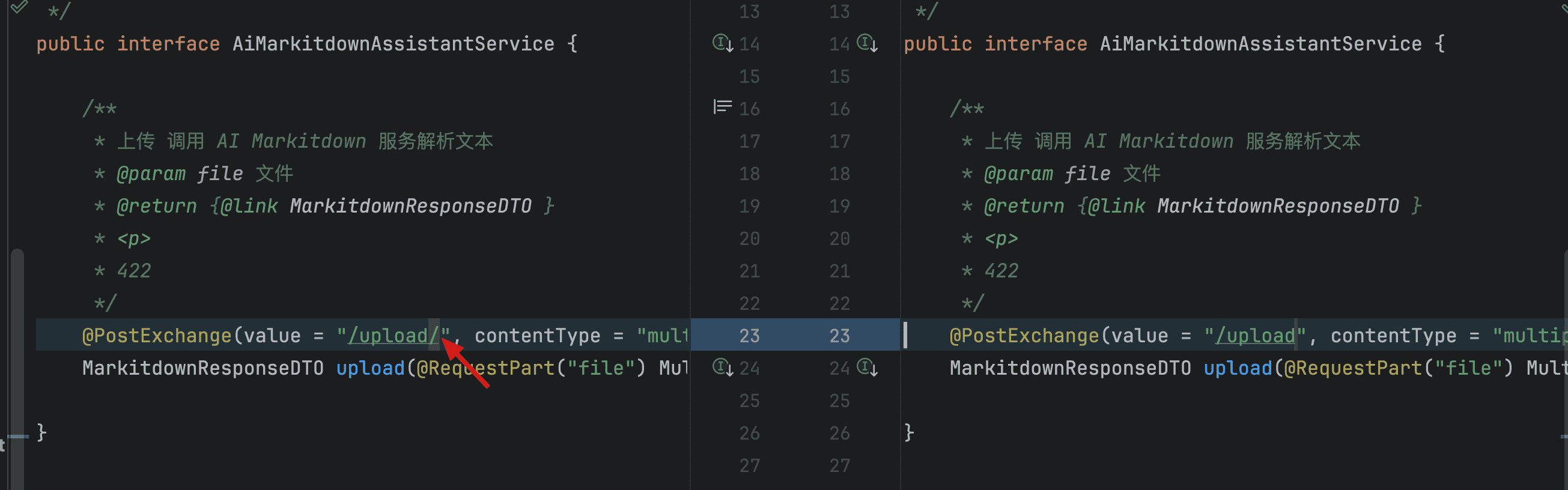
解决方案:
MarkItDown 服务的镜像有更新,路径有变化,旧版本代码需要改一下(PS:2025-3-1 已更新 fix)
找到 AiMarkitdownAssistantService.upload 修改一下路径去掉最后的/
超时与性能问题
调用云厂商大模型超时
问题描述:
比如调用 deepseek api 或者阿里百炼 api 超时,这是不可避免,最近大模型调用频繁,相关的产品服务稳定性不足
解决方案:
在调用对方页面避免慢比较拥堵的时候,比如推理比较慢的时候,可以考虑增加系统默认的超时时间
调用本地大模型超时
问题描述:
比如调用本地 ollama 部署的私有模型超时。
解决方案:
- ollama 本质上是通过你本地资源进行推理,所以确定资源足够,这里查询对应配置关系:ollama 配置
- ollama 本身有很多优化参数配置,并不是开箱即用,需要根据参数优化(并发、keepalive、触发 gpu):参数优化指南
- 如果你们资源足够比如 N 快 H100 H200 的富哥客户,这种卡跑 ollama 纯属浪费,请了解 VLLM VLLM 文档 (PIG AI 也支持直接接入通过 openai 协议)
调用云厂商大模型被限流
问题描述:
在调用云厂商(阿里百炼)的时候,如果同时批量上传多个的文件,调用阿里百炼的模型进行向量的时候可能会触发限流(限流规则:阿里云限流规则)
解决方案:
控制前端上传组件的同时上传数量,限制 office /PDF 的上传大小等
目前来看百炼是基于 APIKEY 级别的限流,PIG AI 后续支持同时配置单一渠道多个 APIKEY 来进行负载,解决这个限流触发
生产构建发布后 SSE 输出卡顿
问题描述:
当我们构建 pigx-ai-ui 使用 nginx 去发布运行的时候,测试 AI 助手聊天会有卡顿
解决方案:直接复制 docker 目录的 pigx-ui.conf
nginx.conf 配置:
模型与文件限制问题
调用大模型提示字数超限制
问题描述:
range of input length should be XXXXX
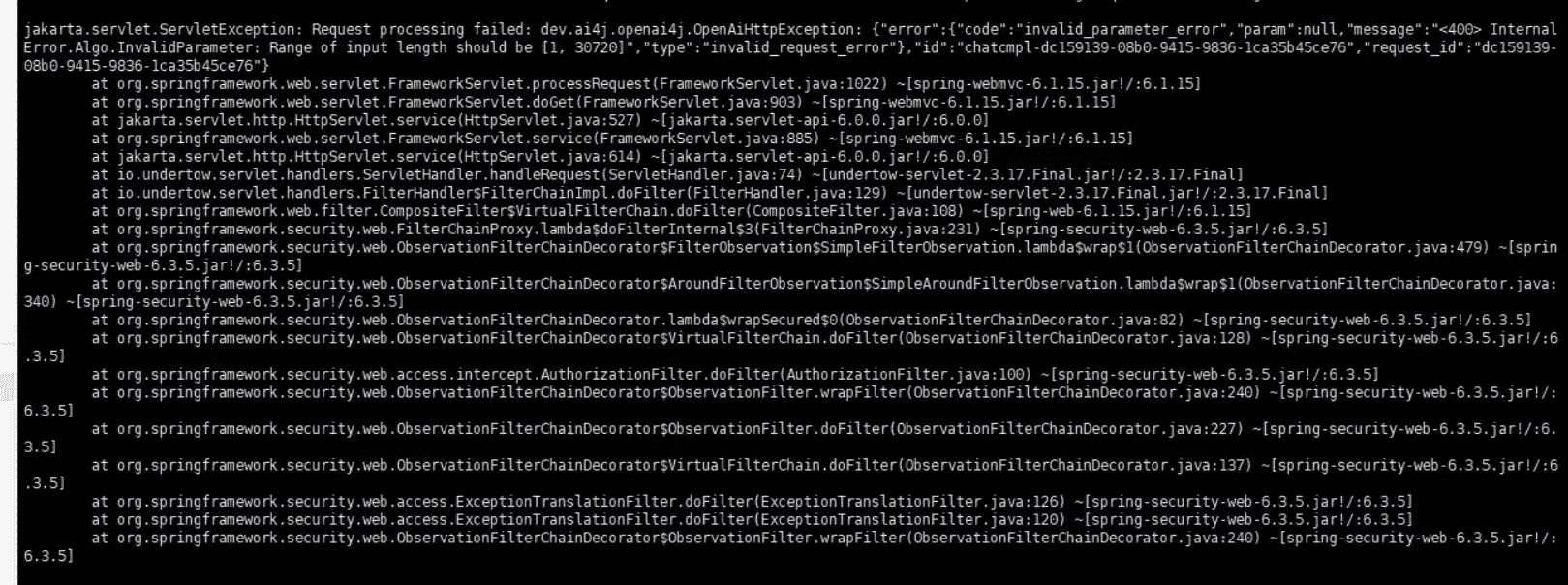
解决方案:
大模型都觉有一个上下文长度的概念,简单来讲就是一次性你最多给它发多少文本
如果你的知识库分片值比较大比如这里是 10000 * 匹配条数 5,一次性 50000 个文字发给大模型,那就回触发这个问题,所以根据你使用的模型 动态修改这个参数
不要超过 2000
调整文件上传大小/数量限制
问题描述:
当前版本前端文件上传有严格的文件大小限制 10MB

解决方案:
主要考虑大 PDF 扫描件的处理效率问题,大文件逐页处理容易导致耗时过长,可能引发大模型调用超时。因此,建议保持现有方案。如有特殊需求,请在前端工程中优化处理。

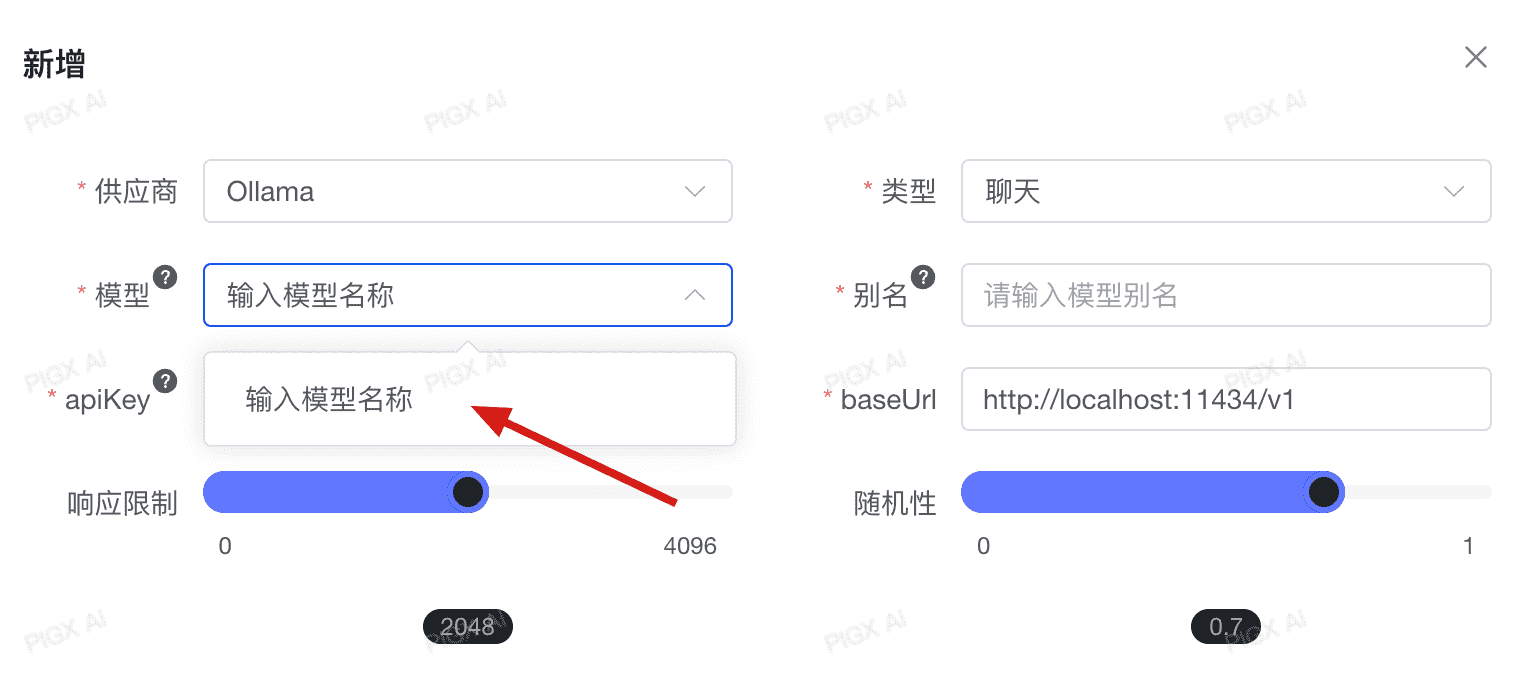
模型管理列表没有对应模型
问题描述:
调用对应厂商的其他模型,但是在模型管理新增的模型列表中没有对应的模型型号
解决方案:
- 在模型管理界面,找到"新增模型"选项
- 在"模型"输入框中,手动输入该厂商的标准模型名称(必须厂商模型名称完全一致)
- 点击"确认"按钮,系统将自动识别并添加该模型
界面与显示问题
前端聊天历史记录如何使用?
问题描述:
从 AI 助手面板点击各个 Agent 进行对话时,发现没有历史记录,不清楚聊天记录保存在哪里。
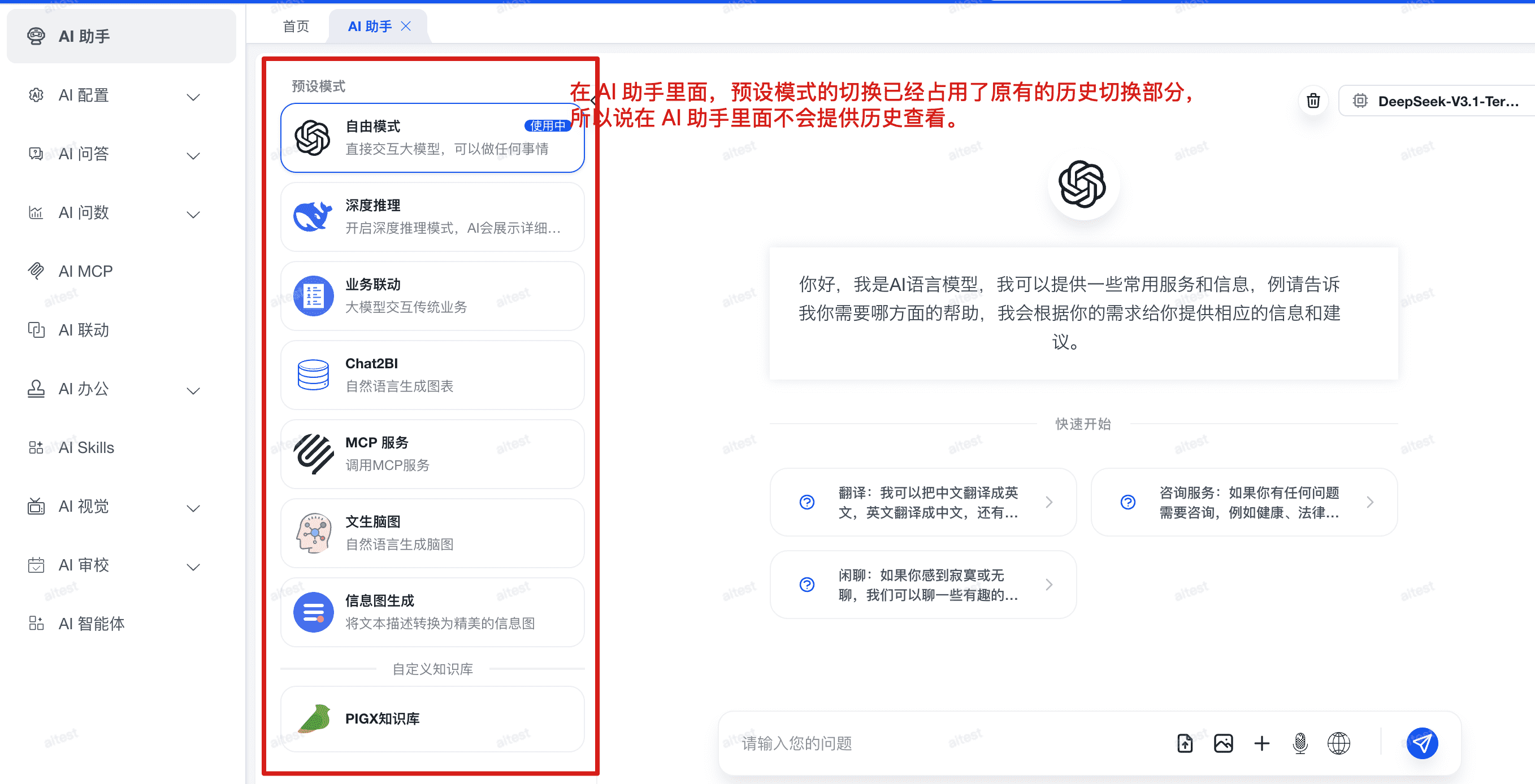
解决方案:
默认情况下,从 AI 助手里面点击各个 Agent 是不会有历史记录的。
AI 助手面板空间有限,聊天区域无法同时展示历史记录列表。因此历史记录需要通过具体的功能菜单查看。
查看历史记录的方式:
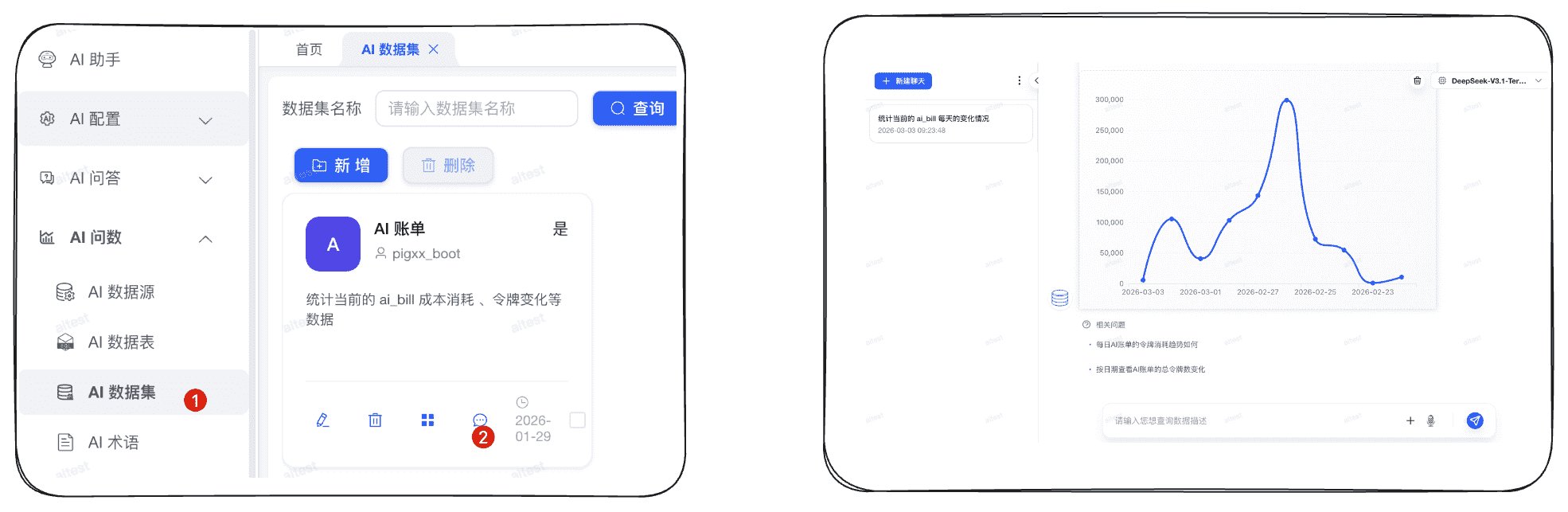
- AI 问答:进入具体的知识库详情页面,即可查看该知识库下的聊天历史
- AI 数据集:进入具体的数据集页面,即可查看对应的聊天历史
文生图生成图片包含水印 PIG AI 信息
问题描述:
生成的图片中出现 PIG AI 水印文字
解决方案:
在提示词管理中维护
