数据标注功能指南
数据标注功能允许管理员对大模型回答进行质量评估和优化,通过标注高质量问答对,实现智能答案复用,提升系统响应能力。
数据标注是 PIGX AI 平台的核心功能之一,帮助管理员:
- 审查和管理所有 AI 对话记录
- 标注高质量的问答对作为标准答案
- 自动复用标注答案,提升响应速度
- 分析对话数据,优化知识库质量
访问入口
在 PIGX AI 管理后台,导航至:AI 大模型 → AI 配置 → 数据标注
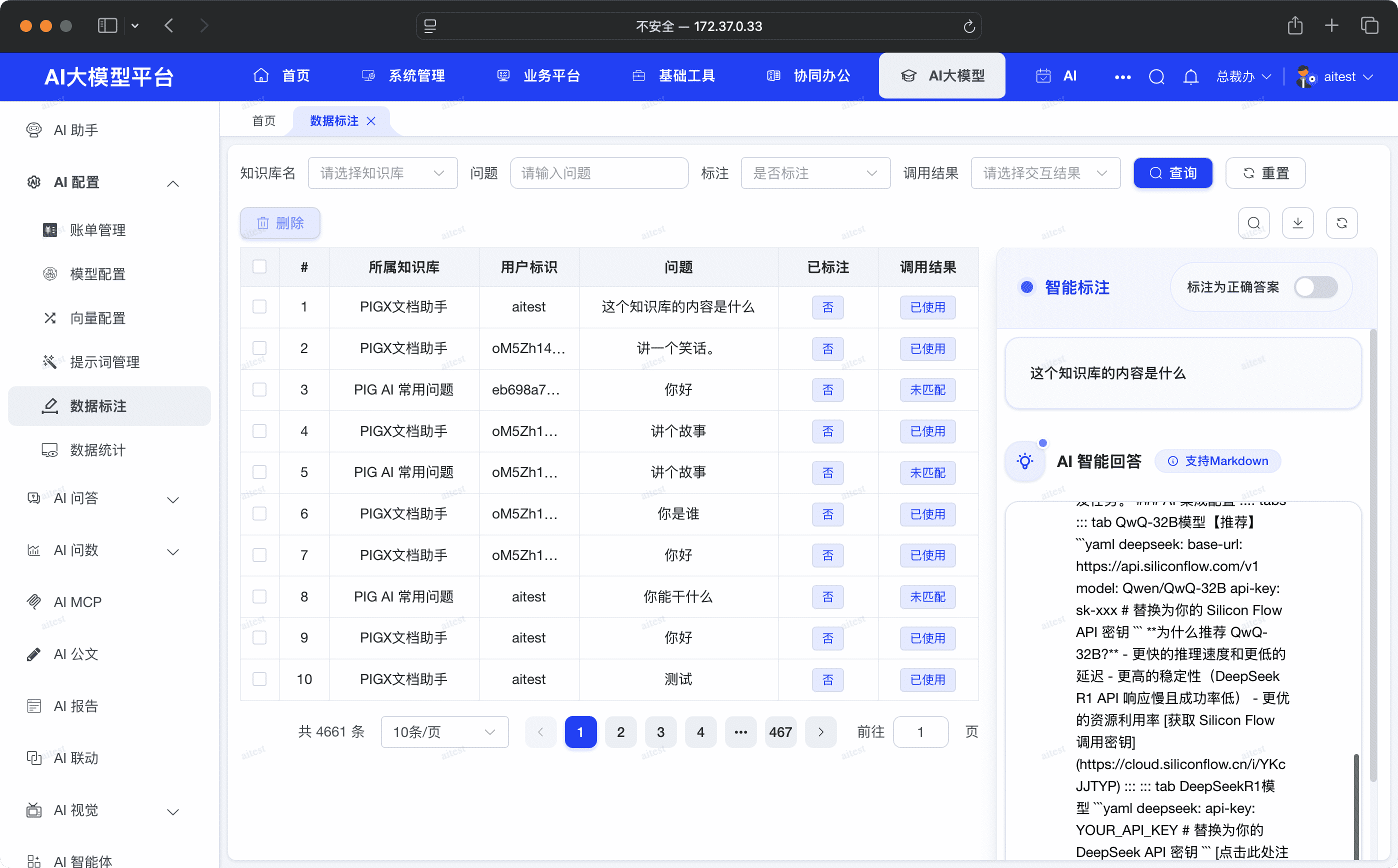
界面功能详解
点击对话记录后,右侧会显示详细的对话内容,按照以下步骤操作:
- 查看对话详情:右侧面板展示完整的问题和 AI 回答内容,支持 Markdown 格式渲染
- 评估答案质量:仔细阅读 AI 生成的回答,判断其是否准确、全面、有价值
- 开启标注开关:对于高质量的回答,开启 "标注为正确答案" 开关
- 自动入库:系统自动将该问答对向量化并存入知识库,用于后续相似问题的快速匹配
标注操作步骤
完整的标注操作流程如下:
- 筛选对话记录:使用筛选条件定位到"已使用"状态的对话记录(这些记录包含 AI 生成的回答)
- 选择记录查看:点击表格中的某条记录,右侧面板会显示完整的问答内容
- 评估回答质量:判断 AI 回答是否准确无误、内容全面、表达清晰、具有参考价值
- 开启标注:如果答案符合标准,开启右上角的 "标注为正确答案" 开关
- 确认保存:系统自动保存标注,并将问答对向量化存入知识库
批量管理
支持批量删除对话记录,可勾选多条记录后点击"删除"按钮进行清理。
知识库配置
要使用数据标注功能,需要在知识库中开启标注数据使用功能:
- 进入知识库管理 → 选择知识库 → 编辑配置
- 找到"标注数据使用"选项,设置为"是"
- 保存配置
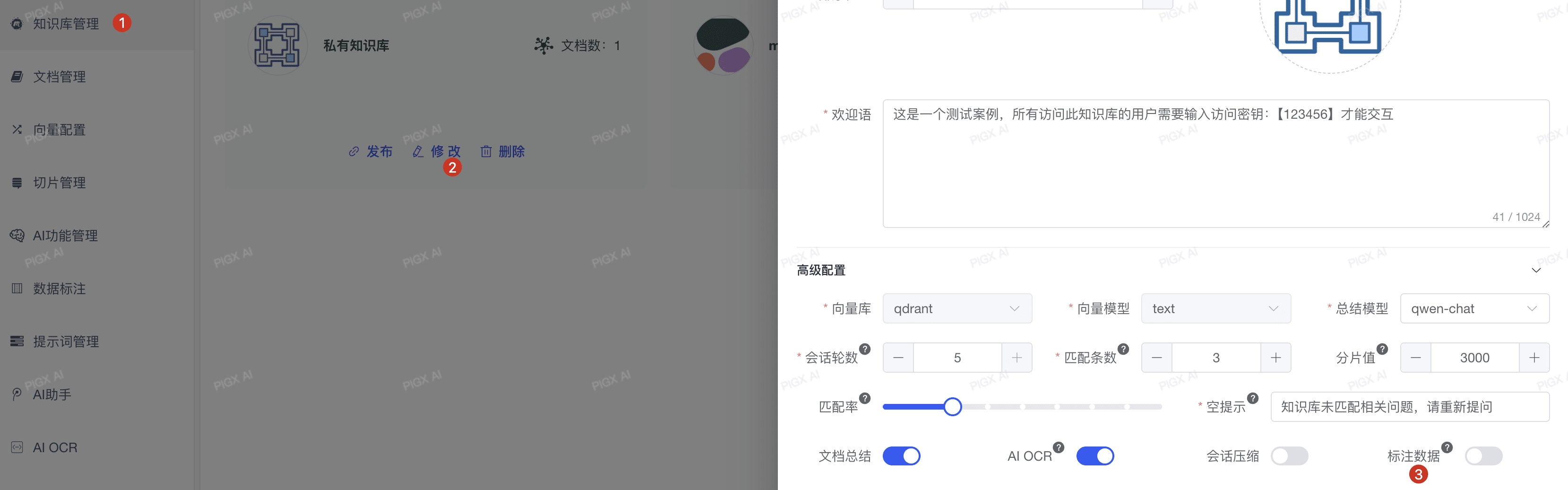
配置说明
只有开启了"标注数据使用"的知识库,才会在用户提问时优先检索标注答案。
工作原理
标注过程
当管理员标注某个问答对时,系统会执行以下操作:
- 向量化问题:使用知识库配置的 Embedding 模型将问题文本转换为向量
- 元数据构建:将问题、答案、数据集 ID、记录 ID 等信息打包为元数据
- 存入向量库:将向量和元数据存入对应知识库的向量数据库(如 Milvus、Qdrant)
- 记录向量 ID:在数据库中记录向量 ID(
qdrantId),便于后续更新或删除
匹配过程
当用户提出新问题时,系统的检索流程:
- 向量化问题:将用户问题转换为向量表示
- 检索标注答案:在向量库中搜索相似度 ≥ 0.9 的标注问答
- 判断匹配:
- 如果找到高相似度匹配(≥ 0.9),直接返回标注答案
- 如果未找到匹配,进入正常 RAG 流程(检索文档 → 调用大模型)
相似度阈值:0.9(高精度匹配)
向量相似度
向量相似度采用余弦相似度计算,范围 0-1。≥ 0.9 为高度相似,视为同一问题;0.7 - 0.9 为较相似,但不足以直接复用;< 0.7 相似度低,走正常 RAG 流程。
核心代码实现
标准问答策略实现位于:
关键逻辑:
优势与价值
1. 提升响应速度
- 向量检索响应时间 < 100ms,无需调用大模型节省 Token 成本,准确度 100%(人工确认的答案)。
- 大模型生成时间 1-5 秒,消耗 Token 产生费用,准确度依赖模型质量和知识库内容。
2. 保证回答一致性
对于高频问题(如"如何重置密码"、"部署步骤是什么"),确保每次都返回经过人工审核的标准答案,避免 AI 生成的随机性。
3. 持续优化知识库
通过不断标注高质量问答对,逐步构建起一个精选问答知识库,随着标注数据的积累,系统的响应质量会持续提升。
4. 降低运营成本
- 减少大模型调用次数:命中标注答案时无需调用 GPT/Claude 等商业模型
- 节省 Token 费用:对于高频问题,成本节省可达 90% 以上
- 提升用户体验:更快的响应速度,更一致的答案质量
本页目录