语音识别功能指南
SenseVoiceSmall 模型是阿里云通义实验室开发的一款音频基础模型,具备多种音频理解能力,包括自动语音识别(ASR)、语种识别(LID)、语音情感识别(SER)以及声学事件分类(AEC)和检测(AED)。
模型优势
该模型专注于高精度的多语言语音识别,支持超过 50 种语言,识别效果优于 Whisper 模型。
我们可以通过 siliconflow 平台接入已经部署的 SenseVoiceSmall 模型,实现语音转文字功能。
准备工作
注册 siliconflow 平台,并获取 API Key。

配置语音模型
在 PIGX 管理后台进入 AI 模型管理页面,添加 SenseVoiceSmall 语音识别模型配置:
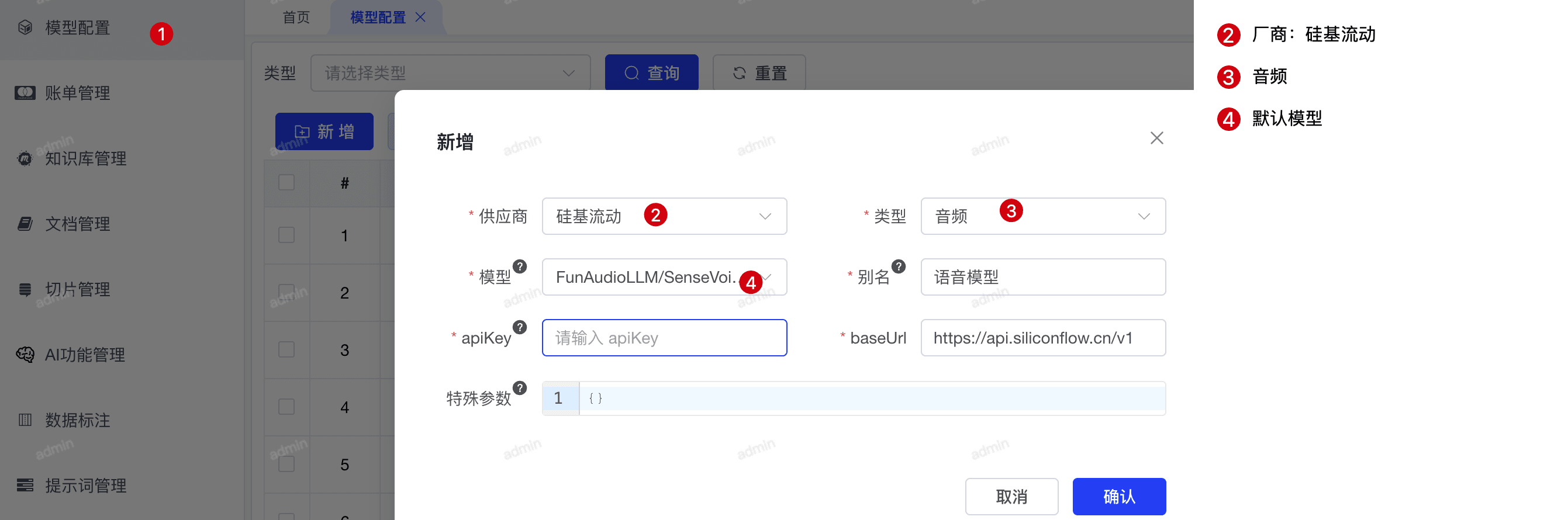
配置参数说明:
- 模型名称: FunAudioLLM/SenseVoiceSmall
- API Key: 填入从 siliconflow 平台获取的密钥
- 模型类型: 选择"语音识别"
- 基础地址: https://api.siliconflow.cn/v1
测试使用
HTTPS 协议要求
站点发布必须启用 HTTPS。引入语音录制功能需要依赖浏览器的 HTML5 接口,浏览器对录音功能的限制要求页面必须在 HTTPS 协议下运行。
配置完成后,在 AI 对话界面点击麦克风图标即可开始语音输入:

使用步骤
- 点击对话框右侧的麦克风图标开始录音
- 说话完成后再次点击麦克风图标停止录音
- 系统自动将语音转换为文字并发送到对话框
- AI 将基于识别的文字内容进行回复
识别效果
支持中文、英文等 50+ 种语言,识别准确率高,支持情感识别和声学事件检测。
本页目录