AI 慧眼功能指南
AI 慧眼是基于视觉大模型的智能 OCR(光学字符识别)系统,通过 AI 模型的视觉理解能力,实现非标准化图片的结构化数据提取。相比传统 OCR 接口,AI 慧眼具有更强的灵活性和适应性,可自定义识别字段,适用于各类票据、证件、表单等场景。
💡核心优势
支持自定义字段提取、灵活的模板配置、可视化标注编辑、双模型协同识别

快速开始
前置准备
系统需要配置两类 AI 模型:
| 模型类型 | 作用 | 推荐模型 |
|---|
| 视觉模型 | 识别图片中的文字内容 | Qwen-VL、GPT-4V、Claude-3 |
| 聊天模型 | 结构化数据提取(高级模式) | GPT-4、Claude-3.5、Qwen-Plus |
⚠模型配置
在使用 AI 慧眼前,请先在「模型管理」中配置好视觉模型和聊天模型
使用流程
创建 OCR 配置
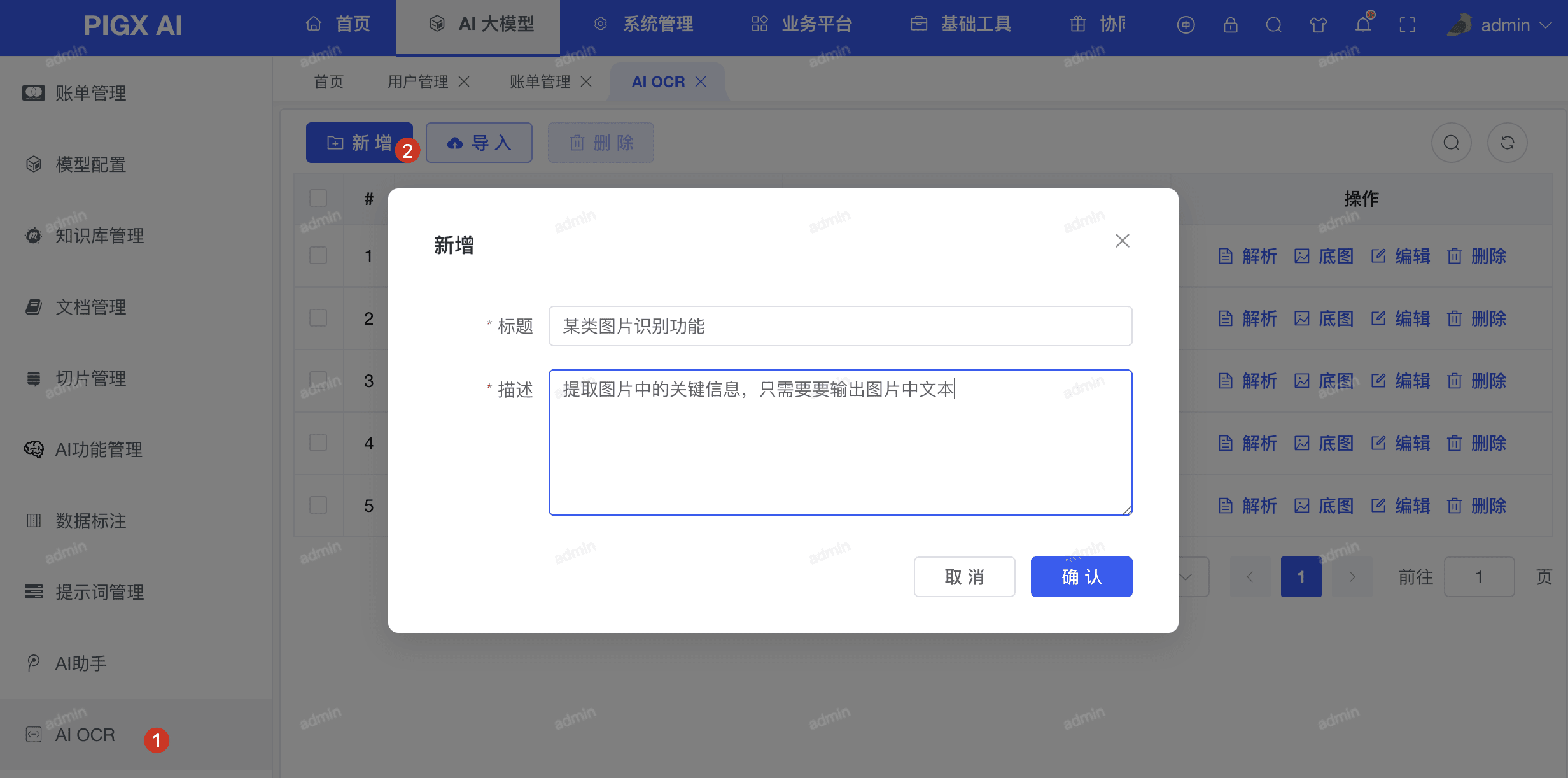
以营业执照识别为例:
- 点击「新增」按钮
- 填写基本信息
| 字段 | 说明 | 示例 |
|---|
| 标题 | OCR 配置名称 | 营业执照识别 |
| 描述 | 识别内容说明 | 从给定的图片中获取企业名称、成立时间信息 |
配置识别模板
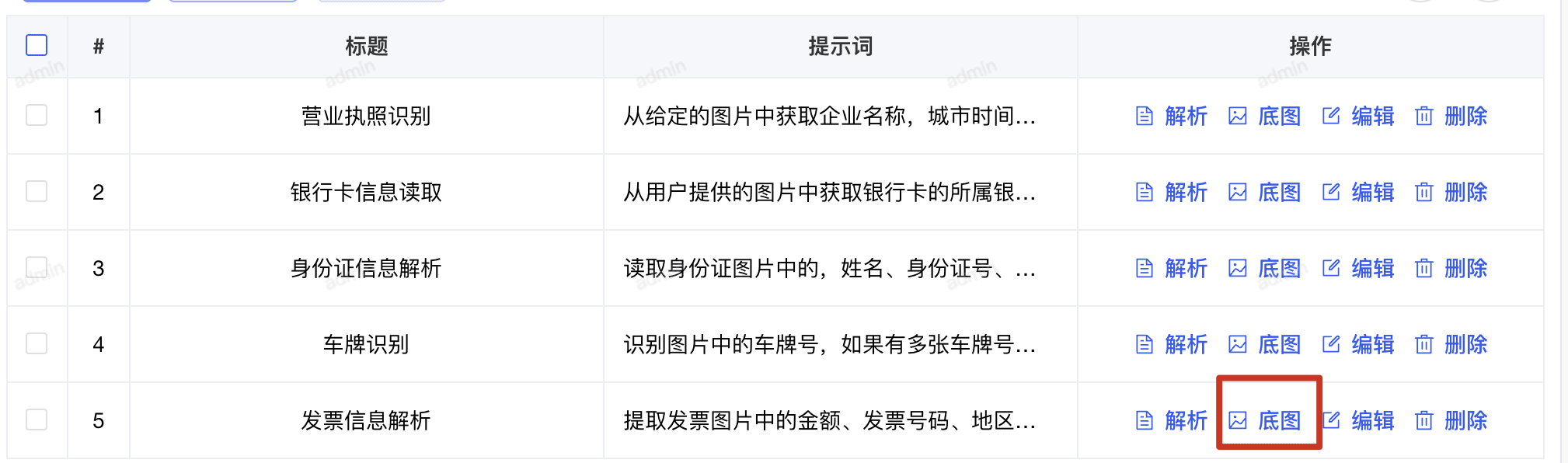
- 上传底图
上传与待识别图片类似的模板图(如营业执照样本)

- 定义字段
在底图上标注需要提取的字段区域
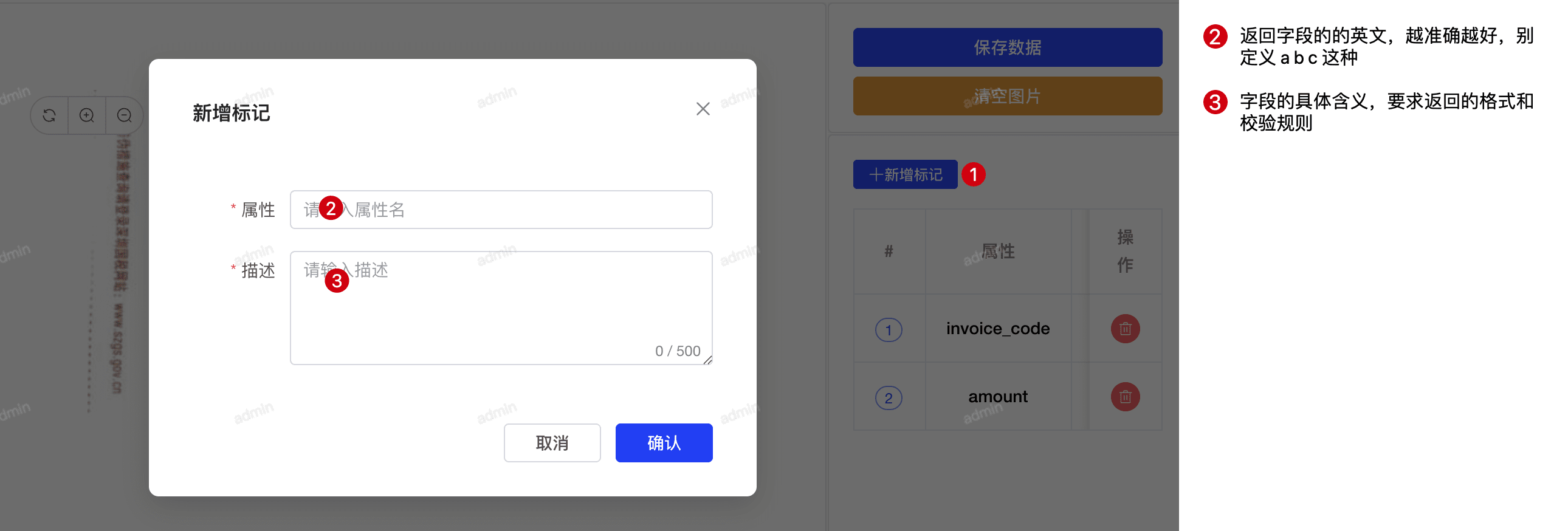
支持的字段类型:
- 文本字段(String)
- 布尔字段(Boolean)
- 自定义类型
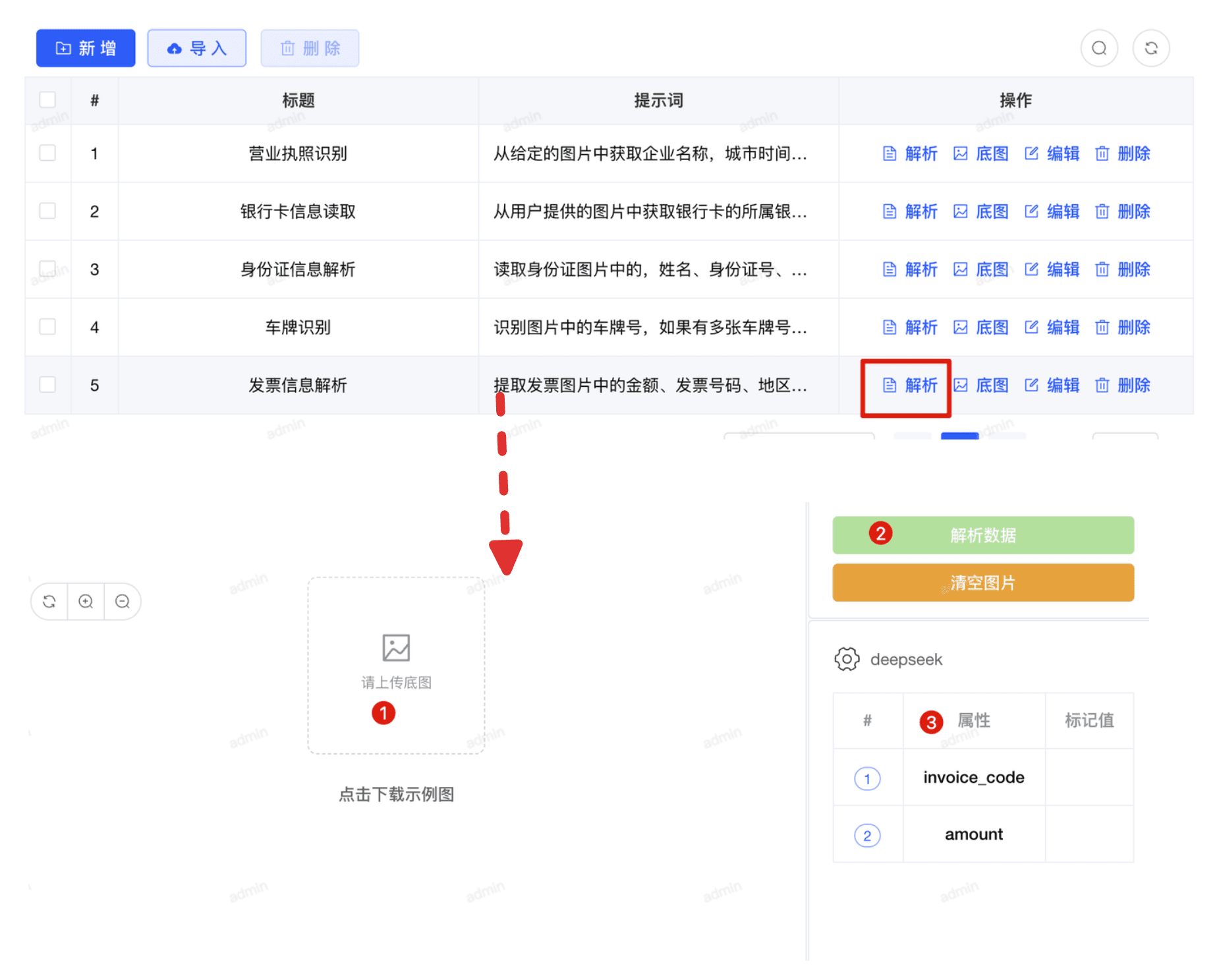
- 测试解析
上传实际图片进行测试,验证识别效果
技术架构
前端实现
前端页面位于 pigx-ui-pro/src/views/knowledge/ocr/,采用卡片列表展示 OCR 配置。
核心组件
主页面 (index.vue)
卡片式展示所有 OCR 配置,支持:
- 查看已标注的字段信息
- 编辑底图和字段配置
- 测试图片识别
- 导出配置
可视化标注页面 (KonvaPage.vue)
基于分屏布局实现图片标注功能:
// 图片缩放和旋转
function handleWheel(event: WheelEvent) {
const delta = -Math.sign(event.deltaY) * SCALE_FACTOR
const newScale = scale.value + delta
// 限制缩放范围 0.1 - 10
scale.value = Math.max(MIN_SCALE, Math.min(MAX_SCALE, newScale))
}
function rotateImage(angle: number) {
rotation.value = (rotation.value + angle + 360) % 360
}
控制面板 (components/ControlPanel.vue)
- 保存配置按钮
- 解析图片按钮
- 清空底图按钮
- 高级解析模式切换
数据展示 (components/DataDisplay.vue)
API 接口定义
// src/api/knowledge/ocr.ts
// 分页查询 OCR 配置列表
export function fetchList(query?: Object) {
return request({
url: '/knowledge/ocr/page',
method: 'get',
params: query,
})
}
// 解析图片
export function parseObj(obj?: Object) {
return request({
url: '/knowledge/ocr/parse',
method: 'post',
data: obj,
timeout: 100000, // 100秒超时
})
}
// 新增配置
export function addObj(obj?: Object) {
return request({
url: '/knowledge/ocr',
method: 'post',
data: obj,
})
}
后端实现
后端服务位于 pigx-knowledge 模块,支持两种识别模式。
请求处理流程
核心代码
控制器 (AiOcrConfController.java)
@PostMapping("/parse")
@HasPermission("knowledge_ocr_add")
public R parse(@RequestBody AiOcrConfEntity aiOcrConf) {
return aiOcrConfService.parseImage(aiOcrConf);
}
服务层 (AiOcrConfServiceImpl.java)
识别逻辑分为两种模式:
1. 普通模式(依赖视觉模型的结构化能力)
if (YesNoEnum.NO.getCode().equals(aiOcrConf.getHigherAnalyze())) {
// 构建 JSON Schema 用户消息
UserMessage userJsonMessage = UserMessage.from(
PromptBuilder.render(OCR_IMAGE_USER_JSON,
Map.of("jsonSchema", getJsonSchema(aiOcrConf, fieldDTOList))
)
)
// 使用视觉模型进行 OCR 识别
Pair<ChatModel, AiAssistantService> visionModel =
modelProvider.getAiVisionAssistant()
ChatResponse response = visionModel.getKey()
.chat(systemMessage, userJsonMessage, userMessage)
// 修复 JSON 格式
return R.ok(JSONRepairUtil.repair(response.aiMessage().text()))
}
2. 高级模式(双模型协同)
// 第一步:视觉模型进行 OCR 文字识别
Pair<ChatModel, AiAssistantService> visionModel =
modelProvider.getAiVisionAssistant()
ChatResponse ocrResponse = visionModel.getKey()
.chat(systemMessage, userMessage)
// 第二步:文本模型按 JSON Schema 提取结构化数据
Triple<ChatModel, AiAssistantService, String> jsonModel =
modelProvider.getAiJSONAssistant(aiOcrConf.getChatModelName())
ChatResponse structuredResponse = jsonModel.getLeft()
.chat(buildChatRequest(confEntity, ocrResponse.aiMessage().text(),
fieldDTOList, jsonModel.getRight()))
return R.ok(JSONRepairUtil.repair(structuredResponse.aiMessage().text()))
💡双模型协同优势
高级模式将 OCR 识别和结构化提取分离,可以使用不同模型的优势,提高识别准确率和字段提取精度
JSON Schema 构建
系统根据用户定义的字段自动构建 JSON Schema:
private JsonSchema getJsonSchema(AiOcrConfEntity confEntity,
List<LlmOCRFieldDTO> fieldDTOList) {
JsonObjectSchema.Builder builder = JsonObjectSchema.builder()
.description(confEntity.getOcrPrompt())
// 遍历字段列表构建 Schema
fieldDTOList.forEach(field -> {
if ("Boolean".equals(field.getType())) {
builder.addBooleanProperty(field.getKey(), field.getDescription())
} else {
builder.addStringProperty(field.getKey(), field.getDescription())
}
})
return builder.build()
}
提示词模板
OCR 系统提示词 (ocr-image.st)
你是一个专业的 OCR 文字识别助手。
请仔细识别图片中的所有文字内容。
OCR 用户 JSON 提示词 (ocr-image-user-json.st)
请从图片中提取以下字段信息,严格按照 JSON Schema 格式返回:
{jsonSchema}
OCR 系统 JSON 提示词 (ocr-system-json.st)
你是一个数据提取专家,擅长从文本中提取结构化数据。
请严格按照 JSON Schema 格式输出结果。
进阶功能
高级解析模式
使用单一视觉模型完成识别和结构化,速度快,成本低,适合字段简单的场景
切换方式:在字段配置界面开启「高级解析」开关
字段类型支持
| 类型 | 说明 | 示例 |
|---|
| String | 文本字段 | 企业名称、地址、联系方式 |
| Boolean | 布尔字段 | 是否盖章、是否过期 |
应用场景
营业执照识别
- 企业名称
- 统一社会信用代码
- 法定代表人
- 成立日期
- 经营范围
身份证识别
发票识别
表单识别
常见问题
识别结果不准确
💡优化建议
- 上传清晰的高分辨率图片
- 确保底图模板与实际图片相似
- 使用高级解析模式提高准确率
- 在字段描述中添加更详细的说明
JSON 格式错误
系统内置 JSONRepairUtil 自动修复常见格式问题,如:
解析超时
⚠超时处理
默认超时时间为 100 秒,如遇大图片或复杂识别可能超时,建议:
- 压缩图片大小(推荐 2MB 以内)
- 使用更快的模型
- 减少识别字段数量
模型选择建议
| 场景 | 视觉模型 | 聊天模型 | 说明 |
|---|
| 简单票据 | Qwen-VL | - | 普通模式即可 |
| 复杂证件 | GPT-4V | GPT-4 | 高级模式,提高准确率 |
| 手写表单 | Claude-3 | Claude-3.5 | 手写识别能力强 |
| 批量处理 | Qwen-VL | Qwen-Plus | 成本优化 |