Claude Code 企业级实践
本文介绍在企业级微服务项目(PIGX)中使用 Claude Code 进行高效开发的实践方法,涵盖 IDE 选择、Git Worktree 工作流和提交规范工具的使用。
适用于需要频繁切换功能分支、同时开发多个特性、或需要快速修复线上问题的团队开发场景。
Git Worktree 创建多个工作目录,在不同终端窗口同时运行多个 Claude Code 实例,让不同 AI 会话并行处理不同功能模块,大幅降低等待时间,显著提升整体产出效率。
什么是 Git Worktree
和分支的区别
Worktree 工作方式
允许你在同一个项目仓库下,创建多个不同的文件夹(副本)。每个文件夹都对应一个不同的分支,且它们共享同一个 .git 核心数据源。
优势:
- 每个功能独立目录,互不干扰
- 同时运行多个开发服务器(不同端口)
- 快速切换 IDE 窗口即可切换功能
- 避免频繁的
git stash操作 - 并行开发多个功能,等待 Claude Code 响应时可切换任务
传统 Git 工作方式
就像在一个房间里干活,想换个任务(切分支)就得把桌子清理干净(git stash 或提交未完成代码),然后再摆上新任务的工具。
问题:
- 切换分支前必须清理工作区
- IDE 需要重新索引项目(大型项目可能需要几分钟)
- 本地开发服务器需要重启
- 容易误提交到错误分支
- 频繁的环境切换打断思路
Claude Code Worktree 使用步骤
前置准备:安装 Worktree Skills
Claude Code 提供了专门的 Skills 来简化 Worktree 的创建和管理。首先需要安装 using-git-worktrees 技能:
使用自然语言创建 Worktree
安装 Skills 后,无需手动执行 git worktree 命令,直接通过自然语言告诉 Claude Code 即可:
方式 1:使用斜杠命令
方式 2:自然语言描述
方式 3:明确指定分支名
使用 Skills 后,整个 Worktree 的生命周期管理(创建、使用、删除)都可以通过自然语言完成,无需记忆 Git 命令。
本地开发环境配置 Skill
在企业级微服务开发中,频繁需要查询数据库、操作 Redis 缓存、查看 Nacos 配置等操作。传统方式下,每次都需要向 AI 说明连接信息(主机、端口、用户名、密码),既繁琐又容易出错。
/local-dev-env Skill 将本地开发环境的所有中间件连接信息集中管理,让 AI 能够直接访问本地服务,无需每次重复声明。
Skill 作用
解决的问题
- 避免每次都要告诉 AI "MySQL 地址是 127.0.0.1,用户名 root,密码 root"
- 统一管理所有中间件的连接信息(MySQL、Redis、Nacos)
- AI 自动知道如何连接和操作本地服务
- 减少沟通成本,提升开发效率
包含的服务
- MySQL:127.0.0.1:3306(root/root)
- Redis:127.0.0.1:6379(无密码)
- Nacos:127.0.0.1:8848(nacos/nacos)
- 包含常用操作命令和安全提醒
创建 Skill
在项目根目录的 .claude/skills/ 下创建 local-dev-env 目录,添加 skill.md 文件:
将本地环境信息写入 skill.md,参考格式:
(详细内容参考项目中的 skill 文件)
Redis 操作
Nacos 配置
核心优势
使用 local-dev-env Skill 后,开发体验显著提升:
- 零配置交互:不再需要每次声明连接信息
- 上下文感知:AI 理解"用户表"指的是
pig.sys_user - 安全提醒:Skill 内置安全检查,执行写操作前会提示确认
- 标准化操作:团队成员使用统一的连接方式和命令规范
Skill 文件包含敏感信息(数据库密码等),建议将 .claude/skills/ 添加到 .gitignore,避免提交到代码仓库。团队成员各自维护本地 Skill 配置。
OpenAI Codex 替代方案
在企业级开发中,除了 Claude Code,OpenAI Codex 也是一个优秀的 AI 编程助手选择。
Codex 的优势
国内友好
- 订阅费用相对较低(约 $20/月)
- 账号封禁风险低,适合国内团队长期使用
复杂问题分析
- GPT 5.3 X-High 模型提供深度推理能力
- 适合解决复杂的技术难题和性能瓶颈
- 虽然响应较慢,但结果质量更高
建议团队同时配备 Claude Code 和 Codex。Claude Code 用于快速原型开发和功能迭代,Codex 用于细节优化和 Bug 修复。
何时从 Claude Code 切换到 Codex
在实际开发中,如果遇到以下情况,建议尝试使用 Codex 替代 Claude Code:
反复失败的细节
当你多次要求 Claude Code 实现某个功能,但某个特定的点一直实现不好时:
顽固的 Bug
Bug 修复尝试多次仍未彻底解决:
不要在 Claude Code 第一次失败后立即切换。先尝试 2-3 次优化提示词。如果同一个细节问题反复出现,这是切换到 Codex 的明确信号。
AI 时代代码提交规范
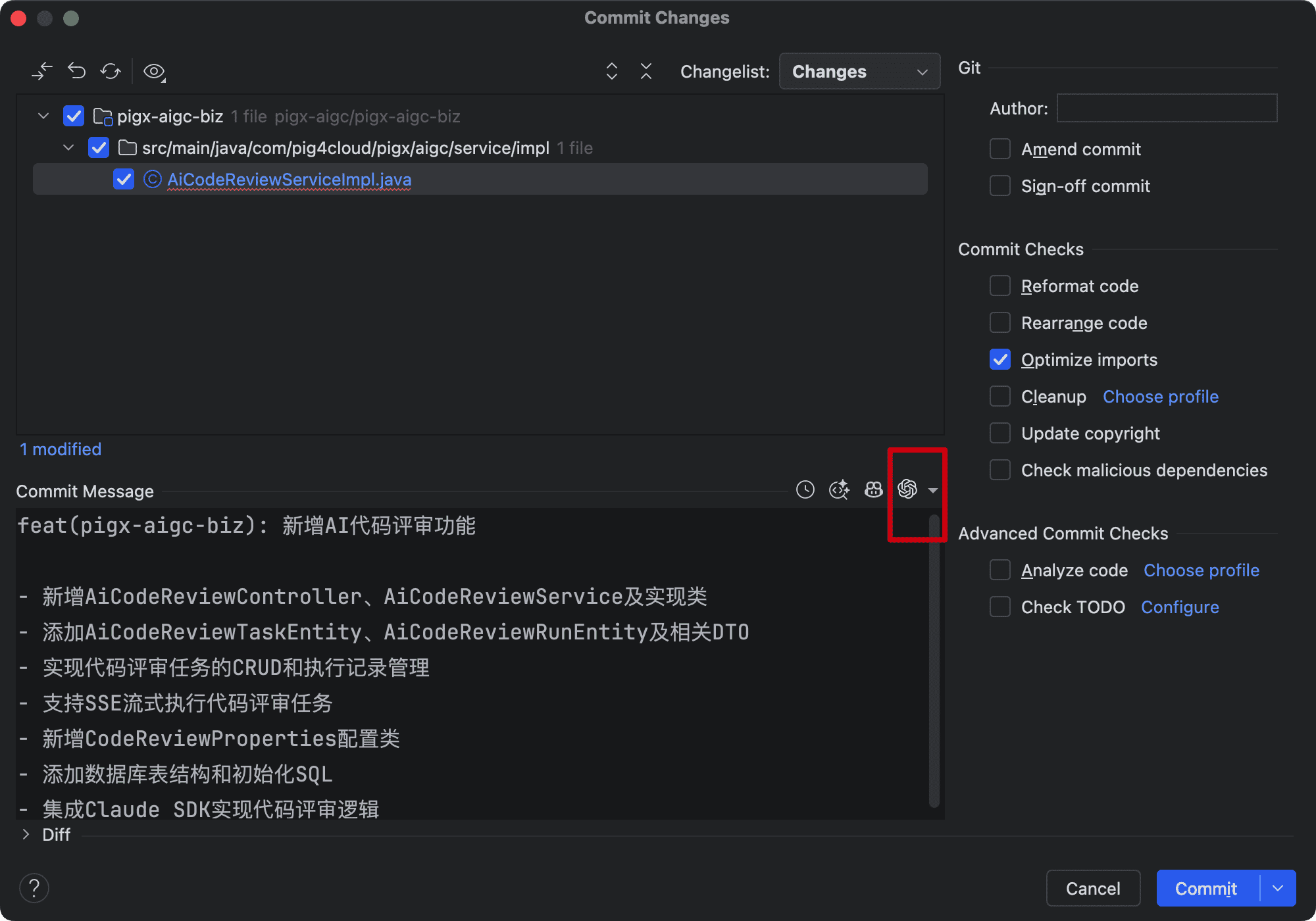
虽然很多 IDE 都提供了这种通过 AI 生成 Git Log 的功能,但是我们需要通过自定义的方式来匹配公司的开发规范和提交规范。
这样,我们就能明确地从 Commit Log 里面分析出来当时提交的一些变更点。
前端工具
推荐大家使用前端使用 VS Code 开发。因为在 Claude Code 这个插件的加持下,就不再需要大家用什么其他的前端工具了。
通过 Ctrl + Shift + P 打开前端配置 settings.json 文件,添加如下配置:
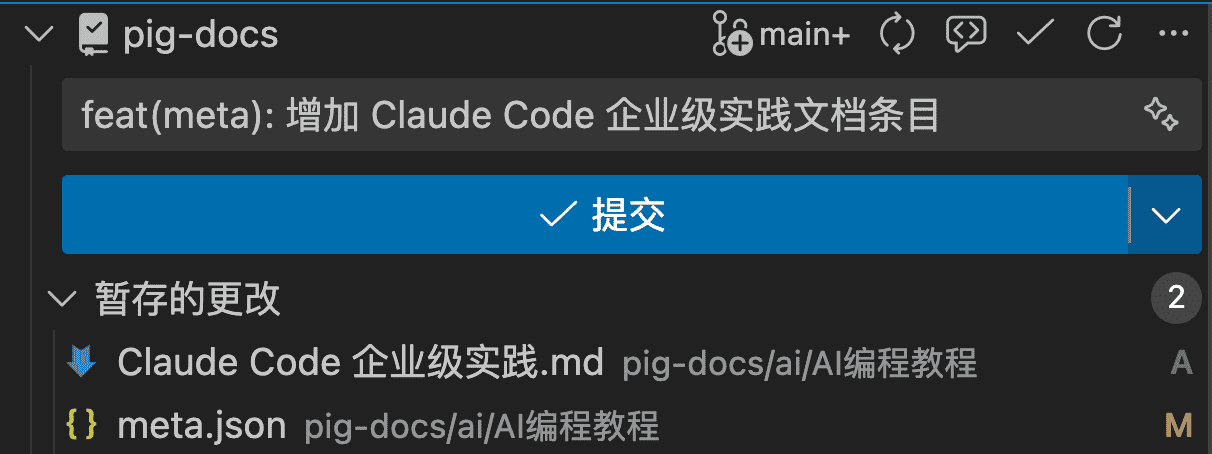
使用 VS Code 自己的 Copilot 进行 Commit Log 的生成:
后端工具
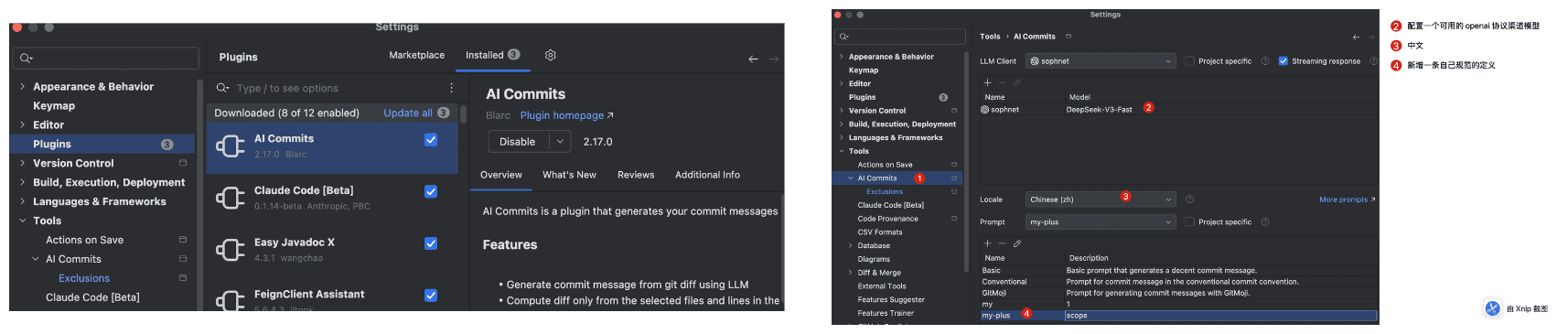
大家在插件市场里面搜索 ai-commit 这个插件。不要使用默认的那些插件,这个插件可以自定义提交规范,然后把我们的规范添加进去。
关于语音输入
在 AI 编程场景中,语音输入正在成为提升效率的重要工具。相比传统键盘输入,语音输入有以下优势:
- 速度更快:正常语速约 160 字/分钟,是键盘输入(约 40 字/分钟)的 4-6 倍
- 降低疲劳:长时间编程时,语音输入能有效减轻手腕和手指的负担
- 思维更流畅:说话比打字更接近自然思考,有助于快速表达复杂的编程思路
得益于大语言模型的发展,现代语音输入工具已经能够:自动去除口头禅("嗯"、"那个")、智能修正语法错误、根据上下文自动格式化内容。这使得语音转文字的准确率和可用性有了质的飞跃。
推荐工具
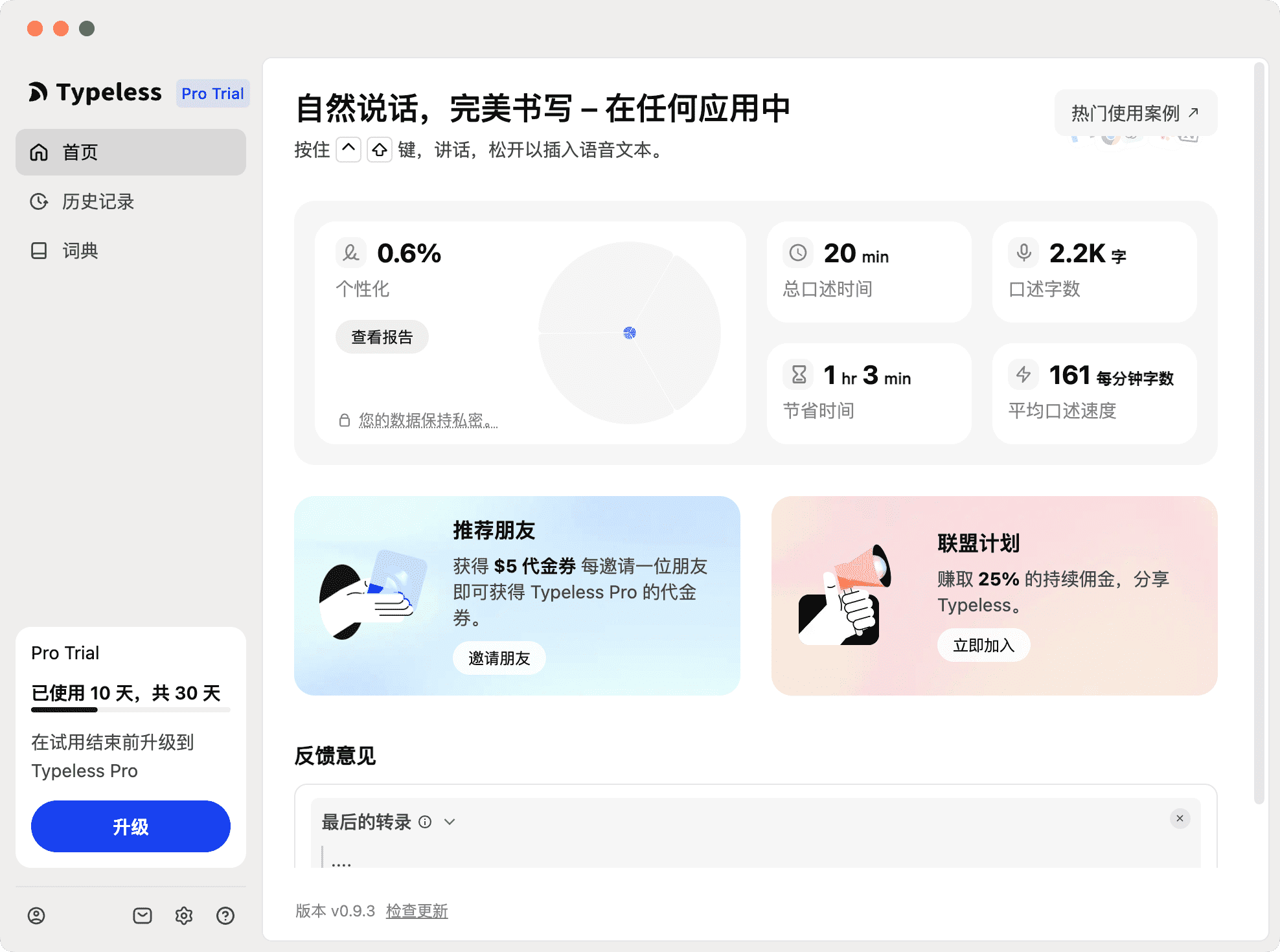
目前笔者在使用 Typeless 作为语音输入,大大提高了效率。
Typeless - 跨平台智能语音输入
- 官网:https://www.typeless.com/
- 支持 macOS、Windows、iOS、Android 全平台
- 核心特性:
- 自动移除填充词("um"、"uh"、"嗯"等)
- 智能去除重复内容,保持语言简洁
- 改变主意时自动编辑,只保留最终想表达的内容
- 自动格式化列表、步骤等结构化内容
- 根据不同应用调整语气(邮件 vs 聊天)
- 支持 100+ 种语言,可混合语言输入
- 个人词典功能,可添加专业术语
Spokenly - Mac 平台首选
- 官网:https://spokenly.app/
- 支持 100+ 种语言,自动语言检测
- 提供本地模式,所有语音数据仅在本地处理,保护隐私
- 集成 GPT-4 等 AI 模型,自动优化语法和格式
- 支持 Agent 模式,可通过语音指令控制 Mac
- 本地模型完全免费,支持离线使用
字节跳动推出的豆包语音输入法在移动端表现出色,具备 15 种方言识别、98.2% 的方言转标准语准确率、上下文感知预测等特性。目前仅支持移动端,PC 版尚未发布。考虑到字节在 AI 领域的技术积累,豆包语音输入法的桌面版值得持续关注。