知识库接入知识图谱
目前知识图谱接入仅支持 Neo4j 数据库,后续会支持其他数据库。
安装 Neo4j
Neo4j 是一个开源的图数据库,用于存储和查询图数据。
使用 Docker 快速安装和启动 Neo4j:
连接配置信息:
- 端口 7474:Neo4j 浏览器 Web 界面访问端口
- 端口 7687:Bolt 协议连接端口(应用程序连接)
- 默认实例:neo4j
- 默认用户名:neo4j
- 默认密码:neo4jneo4j
安装完成后,访问 http://localhost:7474 进入 Neo4j 浏览器界面。
配置向量库
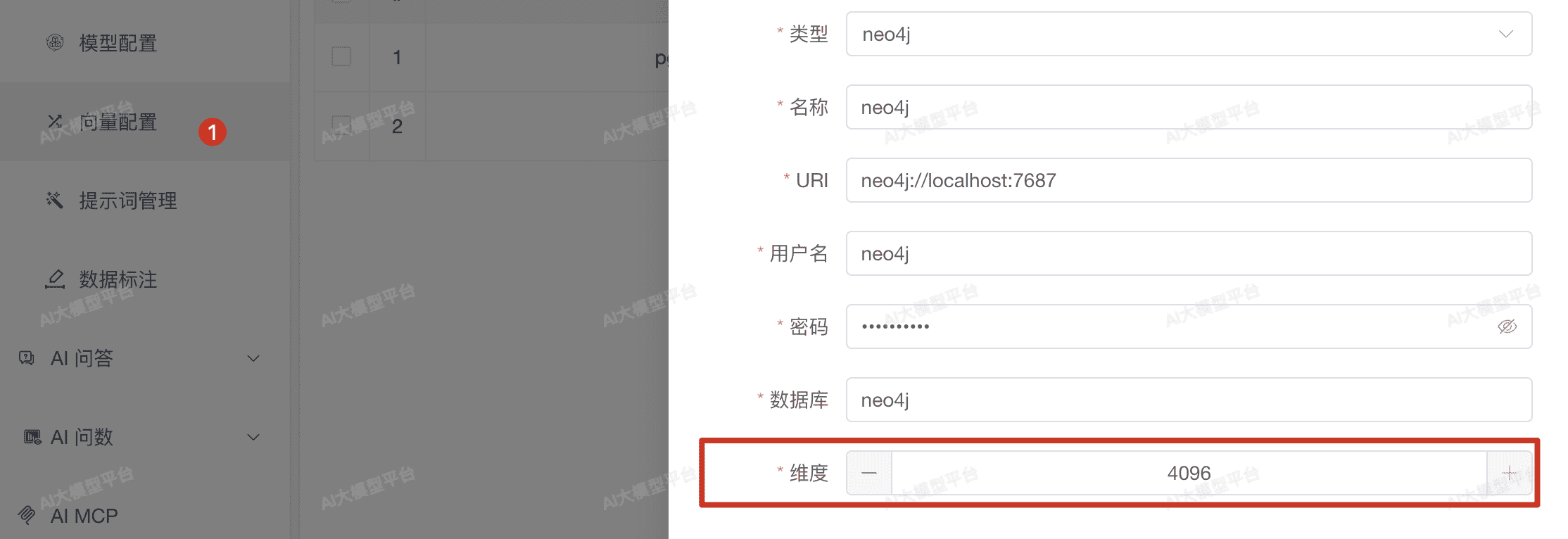
在系统的【向量配置】模块中,点击"新增"按钮来添加 Neo4j 向量存储配置。
进入【向量配置】页面,点击"新增"按钮,选择 Neo4j 向量模式
填写 Neo4j 数据库连接信息:
- 服务地址:localhost:7687(或您的 Neo4j 服务地址)
- 用户名:neo4j
- 密码:neo4jneo4j
- 数据库名:neo4j
配置向量维度参数,该参数必须与您计划使用的向量模型维度保持一致
向量维度配置关键说明: 向量维度设置非常重要,它必须与您后续使用的向量模型输出维度完全匹配。例如:
- 设置维度为 4096,则需要使用输出维度为 4096 的模型(如 Qwen3-Embedding-8B)
- 设置维度为 1024,则需要使用输出维度为 1024 的模型(如 bge-m3) 维度不匹配将导致向量存储和检索失败。
建议根据您的具体需求选择合适的模型:
- 追求最佳效果:选择 Qwen3-Embedding-8B(4096维)
- 平衡性能和效果:选择 bge-m3 或 bge-large-zh-v1.5(1024维)
- 多语言需求:选择 BAAI/bge-m3(1024维)
知识库启用 neo4j
在配置 Neo4j 向量存储后,您需要在知识库中启用 Neo4j 配置。进入知识库管理页面,选择需要配置的知识库。

向量模型维度匹配说明: 在选择向量模型时,必须确保模型的输出维度与之前在 Neo4j 向量配置中设置的维度完全一致:
- 如果在 Neo4j 配置中设置维度为 4096,则只能选择输出维度为 4096 的向量模型(如 Qwen3-Embedding-8B)
- 如果在 Neo4j 配置中设置维度为 1024,则只能选择输出维度为 1024 的向量模型(如 bge-m3、bge-large-zh-v1.5) 维度不匹配将导致向量存储失败,系统无法正常工作。
在知识库列表中找到需要配置的知识库,点击进入详情页面
在知识库配置中找到向量存储选项,选择之前创建的 Neo4j 向量配置
根据 Neo4j 配置中设置的向量维度,选择对应维度的向量模型:
- 4096 维度:选择 Qwen3-Embedding-8B 等 4096 维模型
- 1024 维度:选择 bge-m3、bge-large-zh-v1.5 等 1024 维模型
确认配置无误后,保存知识库设置
图谱查看
使用 Neo4j 知识图谱存储的知识库,会自动为文档生成切片关系图谱。系统将文档内容解析为不同的知识切片,并建立它们之间的关联关系,形成直观的知识图谱结构。
传统 RAG 依赖文本匹配进行检索,难以处理需要跨文档信息汇总的全局性问题。知识图谱通过将文档切片组织为实体-关系网络,实现了:
- 层级关系维护:建立切片与文档、切片与切片之间的结构化关联
- 上下文保持:保留切片在原文档中的位置和语境信息,避免碎片化检索
- 多跳推理支持:通过图遍历发现间接关联的知识节点,提升复杂问题的回答能力
当前版本的关系图主要体现文档切片与整篇文档之间的层级关系(Parent-Child 结构),确保检索时能够追溯切片的完整上下文。后续版本将支持更丰富的语义关系识别,包括实体抽取、关系推理和社区聚类等 GraphRAG 能力。
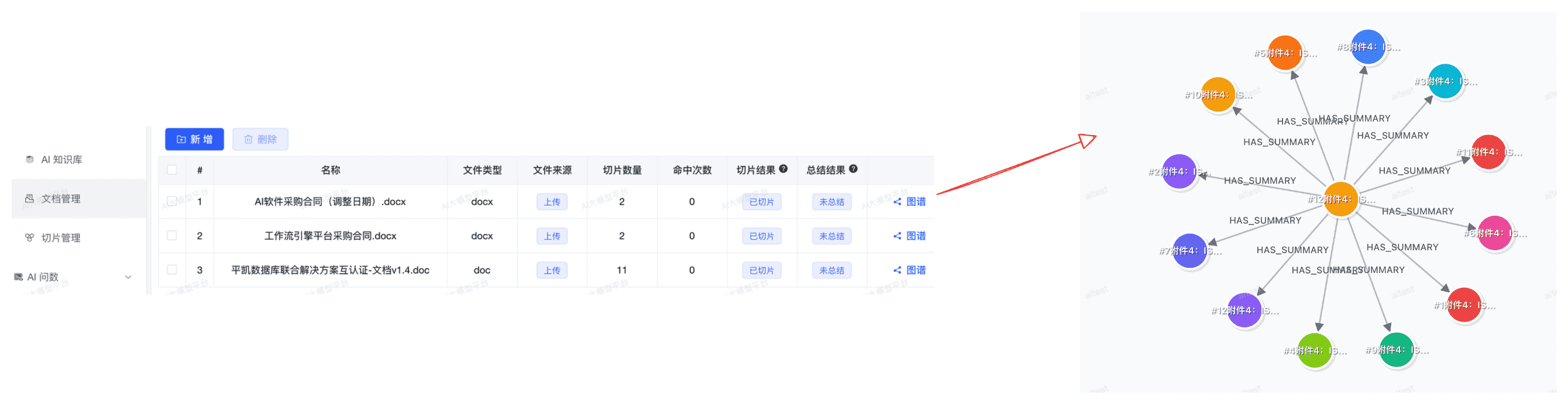
入库原理说明
Neo4jEmbeddingStrategy 会按顺序执行两个阶段:先完成切片向量入库,再执行关系图谱入库。这样可以保证检索侧先拿到可用的向量数据,随后再补齐文档级的图结构和父子关系。
如果阶段 1 失败,整个 processEmbedding 会进入异常处理并将切片标记为失败,阶段 2 不会继续执行。只有切片向量入库完成后,才会开始图谱构建。
1. 生成向量数据入库流程
这一阶段的目标是为每个切片单独生成向量,并写入 Neo4j 向量存储,用于后续相似度检索。实现上会先临时切换为不依赖 parentId 的简单实体创建查询,然后逐个切片生成 embedding、写入元数据,并把返回的向量 ID 回写到切片记录中。
2. 执行关系图谱入库流程
这一阶段的目标是基于整篇文档生成图谱结构。系统会把全部切片内容重新拼装成文档正文,按配置决定是否追加摘要,再通过 Neo4jSummaryGraphIngestor 按段切分文档、生成节点与关系,并最终把文档的图谱状态标记为已完成。
从实现上看,阶段 1 解决的是“让每个切片可检索”,阶段 2 解决的是“让切片之间有结构”。因此 Neo4j 在该方案中同时承担了向量检索存储和图谱关系存储两类职责,前者面向召回,后者面向上下文关联和多跳推理。