知识库标签功能指南
知识库标签功能是 PIGX AI 知识库系统的重要特性,用于对知识库和文档进行分类管理。通过标签功能,您可以:
- 知识库级别标签: 为整个知识库定义分类标签,便于管理和检索
- 文档级别标签: 为单个文档添加标签,支持手动标注和 AI 自动分类
- 标签筛选: 在文档列表中通过标签快速筛选目标文档
- 智能分类: 利用 AI 向量分类技术自动为文档打标签
功能开关

标签功能需要在知识库配置中开启:
- 进入知识库编辑页面
- 切换到「高级配置」选项卡
- 找到「AI标签功能」开关
- 开启后,会出现第 4 个选项卡「标签配置」
功能开关限制
只有开启了 AI 标签功能的知识库,其文档才支持标签管理。
使用指南
1. 配置知识库标签
知识库标签是文档标签的"标签池",文档只能从知识库标签中选择。
操作步骤:
- 编辑知识库,切换到「标签配置」选项卡
- 点击「+ 添加标签」按钮
- 输入标签名称,按 Enter 确认
- 可添加多个标签,点击标签右侧的 ✕ 可删除
- 保存知识库配置
2. 为文档添加标签
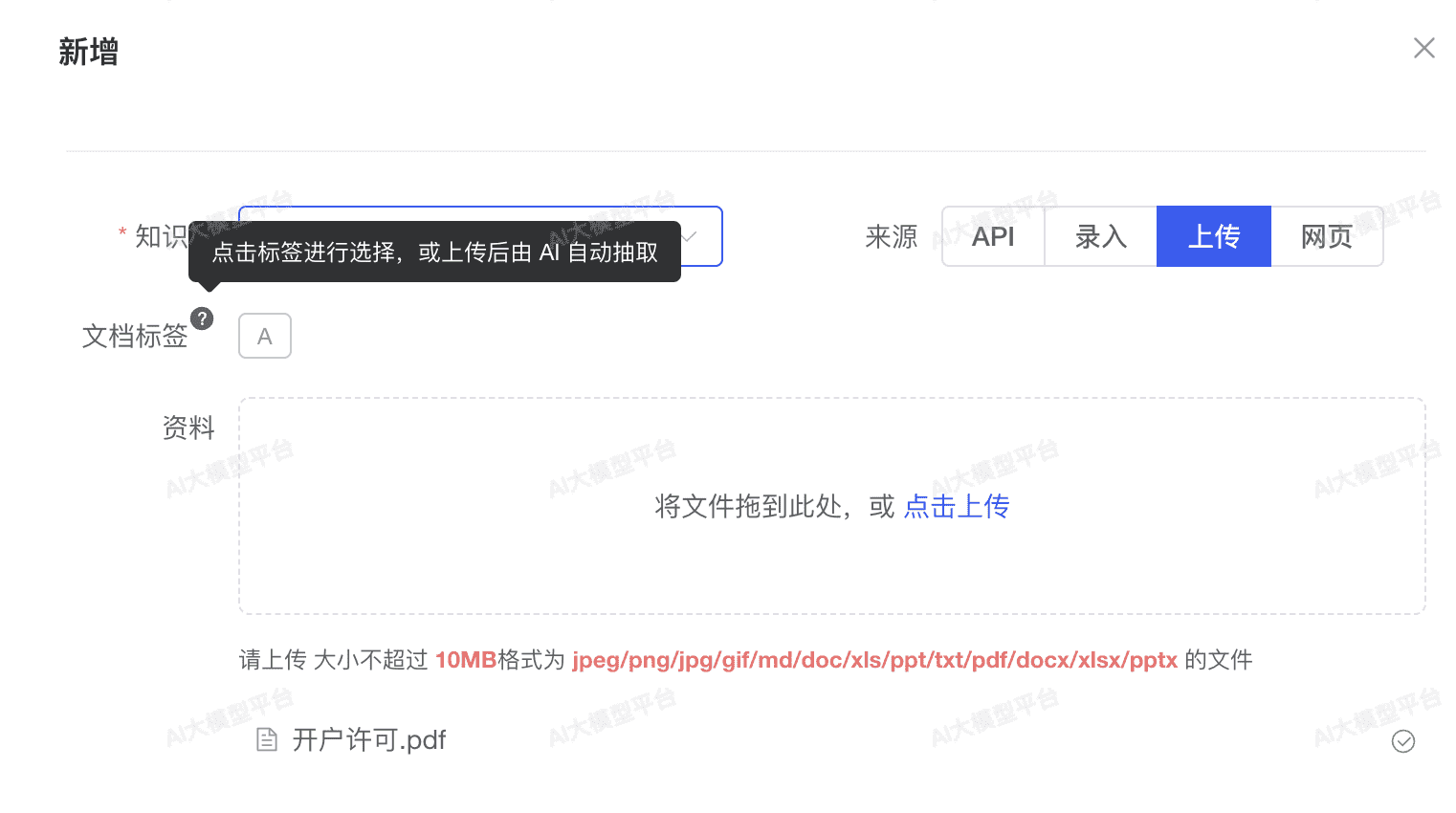
文档标签用于对单个文档进行分类,支持两种方式:
方式一: 手动添加标签
操作步骤:
- 进入知识库的文档列表页面
- 找到目标文档,点击「标签」按钮
- 在弹出的抽屉中,点击选择知识库标签
- 已选中的标签会高亮显示 (深色背景 + ✓ 图标)
- 点击「确认」保存
方式二: AI 自动分类
当文档上传并切片完成后,系统会自动调用 AI 分类器为文档打标签。
触发条件
AI 自动分类需要同时满足以下条件:
- 知识库开启了「AI标签功能」
- 知识库配置了标签列表
- 文档本身没有手动设置标签
- 文档切片成功
后台技术原理
2. AI 自动分类实现
核心服务方法 (pigx-knowledge/service/impl/AiDocumentServiceImpl.java):
AI 分类原理:

关键技术点:
- 使用
@Async异步执行,不阻塞主流程 - 基于向量语义相似度进行分类,而非关键词匹配
- 内容长度限制由
knowledgeProperties.getInMemorySearch().getMaxSegmentSizeInChars()配置
语义分类优势
AI 分类基于向量语义相似度,而非简单的关键词匹配,因此能够更准确地理解文档内容的语义。
向量分类器详解
系统使用 LangChain4j 的 TextClassifier 进行向量分类,核心代码如下:
工作原理:
-
分类器获取 (
classifierProvider.getClassify):- 根据知识库 ID 和标签列表创建分类器实例
- 每个知识库维护独立的分类器,避免跨库干扰
- 标签列表作为分类类别(labels),支持多标签分类
-
文档内容截取 (
StrUtil.subPre):- 限制输入文本长度,避免超出模型 token 限制
- 长度由配置项
knowledgeProperties.getInMemorySearch().getMaxSegmentSizeInChars()控制 - 通常取文档前 N 个字符,包含足够的语义信息
-
向量分类执行 (
classify.classify):- 将文档内容转换为向量表示(embedding)
- 计算文档向量与各标签向量的相似度
- 返回相似度最高的一个或多个标签
LangChain4j 集成:
向量模型支持:
系统支持多种向量模型,包括:
- OpenAI Embeddings:
text-embedding-3-small,text-embedding-3-large - 本地模型: 通过 Ollama 部署的开源模型
- 其他 API: 通义千问、智谱 AI 等国内模型
分类策略:
- 单标签模式: 返回相似度最高的标签
- 多标签模式: 返回相似度超过阈值的所有标签
- 阈值配置: 可通过配置调整分类敏感度
向量分类优势
相比传统的关键词匹配,向量分类能够理解文档的语义内容,即使文档中不包含标签的字面文字,也能准确分类。例如,一篇讨论"机器学习算法"的文档可以被正确分类到"AI技术"标签下。
总结
知识库标签功能通过三层架构实现了灵活的文档分类管理:
- 知识库层: 定义标签池,控制标签功能开关
- 文档层: 支持手动标注和 AI 自动分类
- 查询层: 基于标签快速筛选文档
适用场景
- 文档数量较多,需要分类管理
- 需要快速筛选特定类型的文档
- 希望利用 AI 自动化文档分类
- 需要灵活的多维度分类体系
结合 LangChain4j 向量分类技术,系统能够自动为文档打标签,大大提高了知识库的管理效率。同时,灵活的手动标注功能也保证了分类的准确性和可控性。
本页目录